

Use distcp
Command overview
The distcp command (Distributed Copy) is used to copy data. Its main advantage is that it uses MapReduce to distribute and parallel the data copying, which finds its best application when handling large amounts of data. For more information, see the MapReduce Tutorial.
Additionally, you can use distcp to upload, download, and update the data on object storages such as S3.
To use distcp, several conditions must be met:
-
There must be no path collisions at the source data. Otherwise, the service will return an error. Proceed with caution when using multiple sources.
-
Both the source and destination must run the same version of ADH. To copy data between clusters with different versions, use the WebHDFS protocol.
-
Any operations with the files being copied should be suspended. If a client is writing to a source file or attempting to overwrite a destination file while
distcpis running, the copy will likely fail.
The example command for copying data between clusters using the -update option:
$ hadoop distcp -update hdfs://<HOST1>:8020/tmp hdfs://<HOST2>:8020/tmp2023-09-15 07:43:46,260 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=true, deleteMissing=false, ignoreFailures=false, overwrite=false, append=false, useDiff=false, useRdiff=false, fromSnapshot=null, toSnapshot=null, skipCRC=false, blocking=true, numListstatusThreads=0, maxMaps=20, mapBandwidth=0.0, copyStrategy='uniformsize', preserveStatus=[BLOCKSIZE], atomicWorkPath=null, logPath=null, sourceFileListing=null, sourcePaths=[hdfs://localhost:8020/tmp], targetPath=hdfs://localhost:8020/tmp, filtersFile='null', blocksPerChunk=0, copyBufferSize=8192, verboseLog=false}, sourcePaths=[hdfs://localhost:8020/tmp], targetPathExists=true, preserveRawXattrsfalse
2023-09-15 07:43:46,429 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-jobtracker.properties,hadoop-metrics2.properties
2023-09-15 07:43:46,520 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2023-09-15 07:43:46,520 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2023-09-15 07:43:46,765 INFO tools.SimpleCopyListing: Paths (files+dirs) cnt = 6; dirCnt = 2
2023-09-15 07:43:46,765 INFO tools.SimpleCopyListing: Build file listing completed.
2023-09-15 07:43:46,766 INFO Configuration.deprecation: io.sort.mb is deprecated. Instead, use mapreduce.task.io.sort.mb
2023-09-15 07:43:46,766 INFO Configuration.deprecation: io.sort.factor is deprecated. Instead, use mapreduce.task.io.sort.factor
2023-09-15 07:43:46,793 INFO tools.DistCp: Number of paths in the copy list: 6
2023-09-15 07:43:46,804 INFO tools.DistCp: Number of paths in the copy list: 6
2023-09-15 07:43:46,812 WARN impl.MetricsSystemImpl: JobTracker metrics system already initialized!
2023-09-15 07:43:46,884 INFO mapreduce.JobSubmitter: number of splits:1
2023-09-15 07:43:47,324 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1206860640_0001
2023-09-15 07:43:47,326 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-09-15 07:43:47,459 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2023-09-15 07:43:47,459 INFO tools.DistCp: DistCp job-id: job_local1206860640_0001
2023-09-15 07:43:47,460 INFO mapreduce.Job: Running job: job_local1206860640_0001
2023-09-15 07:43:47,462 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2023-09-15 07:43:47,468 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-09-15 07:43:47,468 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-09-15 07:43:47,469 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.tools.mapred.CopyCommitter
2023-09-15 07:43:47,501 INFO mapred.LocalJobRunner: Waiting for map tasks
2023-09-15 07:43:47,502 INFO mapred.LocalJobRunner: Starting task: attempt_local1206860640_0001_m_000000_0
2023-09-15 07:43:47,525 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-09-15 07:43:47,525 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-09-15 07:43:47,588 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-09-15 07:43:47,591 INFO mapred.MapTask: Processing split: file:/tmp/hadoop/mapred/staging/admin1599424582/.staging/_distcp15296078/fileList.seq:0+1192
2023-09-15 07:43:47,597 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-09-15 07:43:47,597 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-09-15 07:43:47,605 INFO mapred.CopyMapper: Copying hdfs://localhost:8020/tmp to hdfs://localhost:8020/tmp/tmp
2023-09-15 07:43:47,640 INFO mapred.CopyMapper: Copying hdfs://localhost:8020/tmp/test/hadoop-jvm.tgz to hdfs://localhost:8020/tmp/tmp/test/hadoop-jvm.tgz
2023-09-15 07:43:47,652 INFO mapred.RetriableFileCopyCommand: Creating temp file: hdfs://localhost:8020/tmp/.distcp.tmp.attempt_local1206860640_0001_m_000000_0
2023-09-15 07:43:48,462 INFO mapreduce.Job: Job job_local1206860640_0001 running in uber mode : false
2023-09-15 07:43:48,463 INFO mapreduce.Job: map 0% reduce 0%
2023-09-15 07:43:48,698 INFO mapred.CopyMapper: Copying hdfs://localhost:8020/tmp/test to hdfs://localhost:8020/tmp/tmp/test
2023-09-15 07:43:48,708 INFO mapred.CopyMapper: Copying hdfs://localhost:8020/tmp/test/pom.xml to hdfs://localhost:8020/tmp/tmp/test/pom.xml
2023-09-15 07:43:48,717 INFO mapred.RetriableFileCopyCommand: Creating temp file: hdfs://localhost:8020/tmp/.distcp.tmp.attempt_local1206860640_0001_m_000000_0
2023-09-15 07:43:48,900 INFO mapred.CopyMapper: Copying hdfs://localhost:8020/tmp/test/03_02.mov to hdfs://localhost:8020/tmp/tmp/test/03_02.mov
2023-09-15 07:43:48,909 INFO mapred.RetriableFileCopyCommand: Creating temp file: hdfs://localhost:8020/tmp/.distcp.tmp.attempt_local1206860640_0001_m_000000_0
2023-09-15 07:43:59,535 INFO mapred.LocalJobRunner: 66.2% Copying hdfs://localhost:8020/tmp/test/03_02.mov to hdfs://localhost:8020/tmp/tmp/test/03_02.mov [674.9M/1018.9M] > map
2023-09-15 07:44:00,470 INFO mapreduce.Job: map 82% reduce 0%
2023-09-15 07:44:05,536 INFO mapred.LocalJobRunner: 100.0% Copying hdfs://localhost:8020/tmp/test/03_02.mov to hdfs://localhost:8020/tmp/tmp/test/03_02.mov [1018.9M/1018.9M] > map
2023-09-15 07:44:07,014 INFO mapred.CopyMapper: Copying hdfs://localhost:8020/tmp/test/test_file.zip to hdfs://localhost:8020/tmp/tmp/test/test_file.zip
2023-09-15 07:44:07,023 INFO mapred.RetriableFileCopyCommand: Creating temp file: hdfs://localhost:8020/tmp/.distcp.tmp.attempt_local1206860640_0001_m_000000_0
2023-09-15 07:44:11,537 INFO mapred.LocalJobRunner: 88.6% Copying hdfs://localhost:8020/tmp/test/test_file.zip to hdfs://localhost:8020/tmp/tmp/test/test_file.zip [256.1M/289.0M] > map
2023-09-15 07:44:12,412 INFO mapred.LocalJobRunner: 88.6% Copying hdfs://localhost:8020/tmp/test/test_file.zip to hdfs://localhost:8020/tmp/tmp/test/test_file.zip [256.1M/289.0M] > map
2023-09-15 07:44:12,412 INFO mapred.Task: Task:attempt_local1206860640_0001_m_000000_0 is done. And is in the process of committing
2023-09-15 07:44:12,413 INFO mapred.LocalJobRunner: 88.6% Copying hdfs://localhost:8020/tmp/test/test_file.zip to hdfs://localhost:8020/tmp/tmp/test/test_file.zip [256.1M/289.0M] > map
2023-09-15 07:44:12,414 INFO mapred.Task: Task attempt_local1206860640_0001_m_000000_0 is allowed to commit now
2023-09-15 07:44:12,415 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1206860640_0001_m_000000_0' to file:/tmp/hadoop/mapred/staging/admin1599424582/.staging/_distcp15296078/_logs
2023-09-15 07:44:12,416 INFO mapred.LocalJobRunner: 100.0% Copying hdfs://localhost:8020/tmp/test/test_file.zip to hdfs://localhost:8020/tmp/tmp/test/test_file.zip [289.0M/289.0M]
2023-09-15 07:44:12,417 INFO mapred.Task: Task 'attempt_local1206860640_0001_m_000000_0' done.
2023-09-15 07:44:12,424 INFO mapred.Task: Final Counters for attempt_local1206860640_0001_m_000000_0: Counters: 25
File System Counters
FILE: Number of bytes read=191251
FILE: Number of bytes written=697086
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1371500500
HDFS: Number of bytes written=1371500500
HDFS: Number of read operations=48
HDFS: Number of large read operations=0
HDFS: Number of write operations=15
Map-Reduce Framework
Map input records=6
Map output records=0
Input split bytes=150
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=41
Total committed heap usage (bytes)=326631424
File Input Format Counters
Bytes Read=1232
File Output Format Counters
Bytes Written=8
DistCp Counters
Bandwidth in Btyes=57145854
Bytes Copied=1371500500
Bytes Expected=1371500500
Files Copied=4
DIR_COPY=2
2023-09-15 07:44:12,424 INFO mapred.LocalJobRunner: Finishing task: attempt_local1206860640_0001_m_000000_0
2023-09-15 07:44:12,425 INFO mapred.LocalJobRunner: map task executor complete.
2023-09-15 07:44:12,436 INFO mapred.CopyCommitter: About to preserve attributes: B
2023-09-15 07:44:12,441 INFO mapred.CopyCommitter: Preserved status on 0 dir entries on target
2023-09-15 07:44:12,441 INFO mapred.CopyCommitter: Cleaning up temporary work folder: file:/tmp/hadoop/mapred/staging/admin1599424582/.staging/_distcp15296078
2023-09-15 07:44:12,475 INFO mapreduce.Job: map 100% reduce 0%
2023-09-15 07:44:12,476 INFO mapreduce.Job: Job job_local1206860640_0001 completed successfully
2023-09-15 07:44:12,482 INFO mapreduce.Job: Counters: 25
File System Counters
FILE: Number of bytes read=191251
FILE: Number of bytes written=697086
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1371500500
HDFS: Number of bytes written=1371500500
HDFS: Number of read operations=48
HDFS: Number of large read operations=0
HDFS: Number of write operations=15
Map-Reduce Framework
Map input records=6
Map output records=0
Input split bytes=150
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=41
Total committed heap usage (bytes)=326631424
File Input Format Counters
Bytes Read=1232
File Output Format Counters
Bytes Written=8
DistCp Counters
Bandwidth in Btyes=57145854
Bytes Copied=1371500500
Bytes Expected=1371500500
Files Copied=4
DIR_COPY=2
Copy data between two kerberized clusters
To run distcp in a cluster from a different Kerberos realm, you need to establish trust between the clusters. Usually, it is done manually by editing the Kerberos configuration files. For more information on how to set up a trust between clusters manually, see Setting up a Realm Trust.
In this example, the trust is configured via ADCM, and the distcp is called using the Additional nameservices parameter. See more details about the Internal nameservice concept in the HDFS service management via ADCM article.
Preparation steps
It is assumed that Kerberos is already installed and configured. To learn more about how to install Kerberos, see Kerberos server settings.
The following information is required to perform the next steps:
-
cluster realms;
-
cluster nameservices (you can find the cluster nameservice in the
dfs.internal.nameservicesparameter on the HDFS configuration page); -
Kerberos server FQDN or IP;
-
NameNodes server FQDN and IP;
-
NameNodes ID (you can find the ID in the NameNode UI:
http://<NameNode IP or FQDN>:9870/); -
Kerberos admin account credentials.
Set up trust
To set up trust between two Kerberos servers via ADCM, perform these actions for both clusters:
-
On the Clusters page, select the desired cluster.
-
Navigate to Services and click at HDFS.
-
Find and fill in the Additional nameservices parameter in the hdfs-site.xml section. For each cluster, specify parameters of the other cluster.
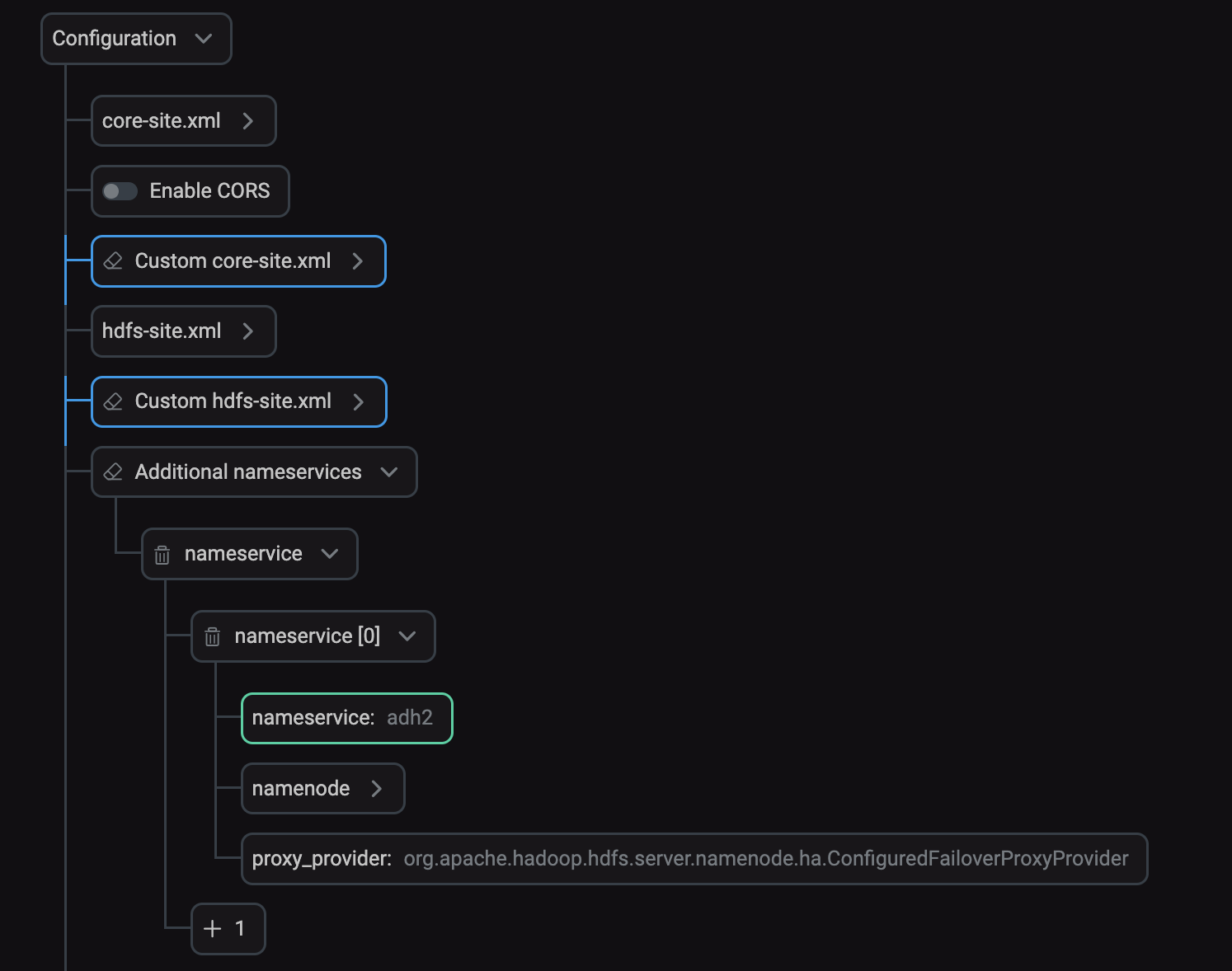 Additional nameservices parameter in ADCM
Additional nameservices parameter in ADCM -
In the hadoop.security.auth_to_local HDFS parameter, paste the following rules that map users of the first cluster to users of the second one:
RULE:[2:$1/$2@$0](hdfs-namenode/.*@<REALM2>)s/.*/hdfs/RULE:[2:$1/$2@$0](hdfs-datanode/.*@<REALM2>)s/.*/hdfs/RULE:[2:$1/$2@$0](hdfs-journalnode/.*@<REALM2>)s/.*/hdfs/RULE:[2:$1/$2@$0](hdfs/.*@<REALM2>)s/.*/hdfs/RULE:[2:$1/$2@$0](yarn-resourcemanager/.*@<REALM2>)s/.*/yarn/RULE:[2:$1/$2@$0](yarn-nodemanager/.*@<REALM2>)s/.*/yarn/RULE:[2:$1/$2@$0](yarn/.*@<REALM2>)s/.*/yarn/RULE:[2:$1/$2@$0](hbase-master/.*@<REALM2>)s/.*/hbase/RULE:[2:$1/$2@$0](hbase-regionserver/.*@<REALM2>)s/.*/hbase/RULE:[2:$1/$2@$0](mapreduce-historyserver/.*@<REALM2>)s/.*/mapred/RULE:[2:$1/$2@$0](hdfs-namenode/.*@<REALM1>)s/.*/hdfs/RULE:[2:$1/$2@$0](hdfs-datanode/.*@<REALM1>)s/.*/hdfs/RULE:[2:$1/$2@$0](hdfs-journalnode/.*@<REALM1>)s/.*/hdfs/RULE:[2:$1/$2@$0](hdfs/.*@<REALM1>)s/.*/hdfs/RULE:[2:$1/$2@$0](yarn-resourcemanager/.*@<REALM1>)s/.*/yarn/RULE:[2:$1/$2@$0](yarn-nodemanager/.*@<REALM1>)s/.*/yarn/RULE:[2:$1/$2@$0](yarn/.*@<REALM1>)s/.*/yarn/RULE:[2:$1/$2@$0](hbase-master/.*@<REALM1>)s/.*/hbase/RULE:[2:$1/$2@$0](hbase-regionserver/.*@<REALM1>)s/.*/hbase/RULE:[2:$1/$2@$0](mapreduce-historyserver/.*@<REALM1>)s/.*/mapred/DEFAULTWhere
<REALM1>and<REALM2>are cluster realms. For more information on how to create these rules, see Hadoop in Secure Mode. -
On the same page, find the User managed hadoop.security.auth_to_local parameter and set it to
true. -
After you configured HDFS parameters for both clusters, reboot the HDFS services with the Apply configs from ADCM option.
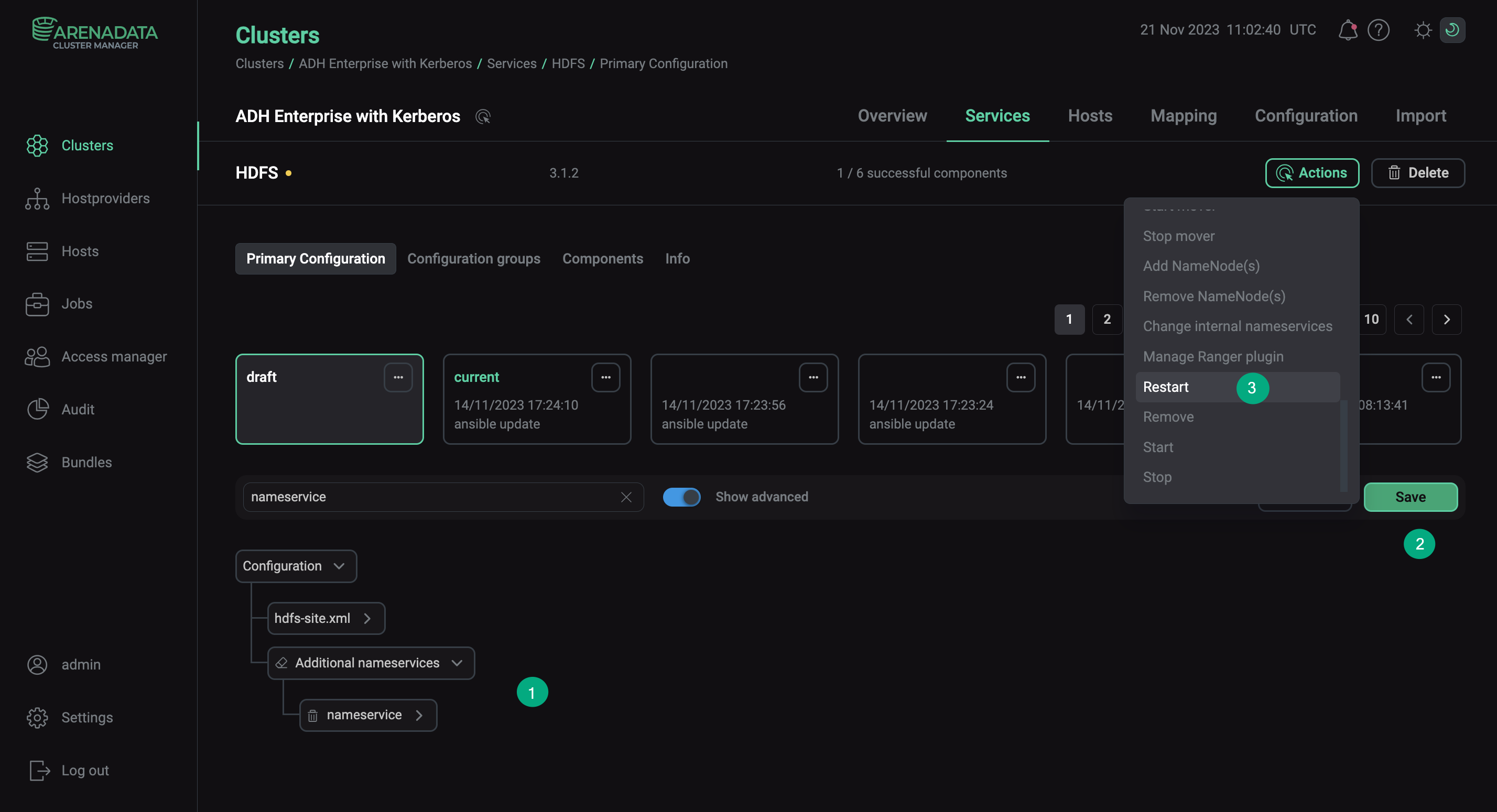 Configure HDFS for Kerberos trust
Configure HDFS for Kerberos trust -
On both Kerberos servers, create a common principal by running the following commands:
$ kadmin.local addprinc -e "aes128-cts-hmac-sha1-96:normal des3-cbc-sha1:normal arcfour-hmac-md5:normal" krbtgt/<REALM1>@<REALM2> $ kadmin.local addprinc -e "aes128-cts-hmac-sha1-96:normal des3-cbc-sha1:normal arcfour-hmac-md5:normal" krbtgt/<REALM2>@<REALM1>Where
<REALM1>and<REALM2>are cluster realms. -
Configure the Additional realms parameter. For each cluster, specify parameters of the other cluster.
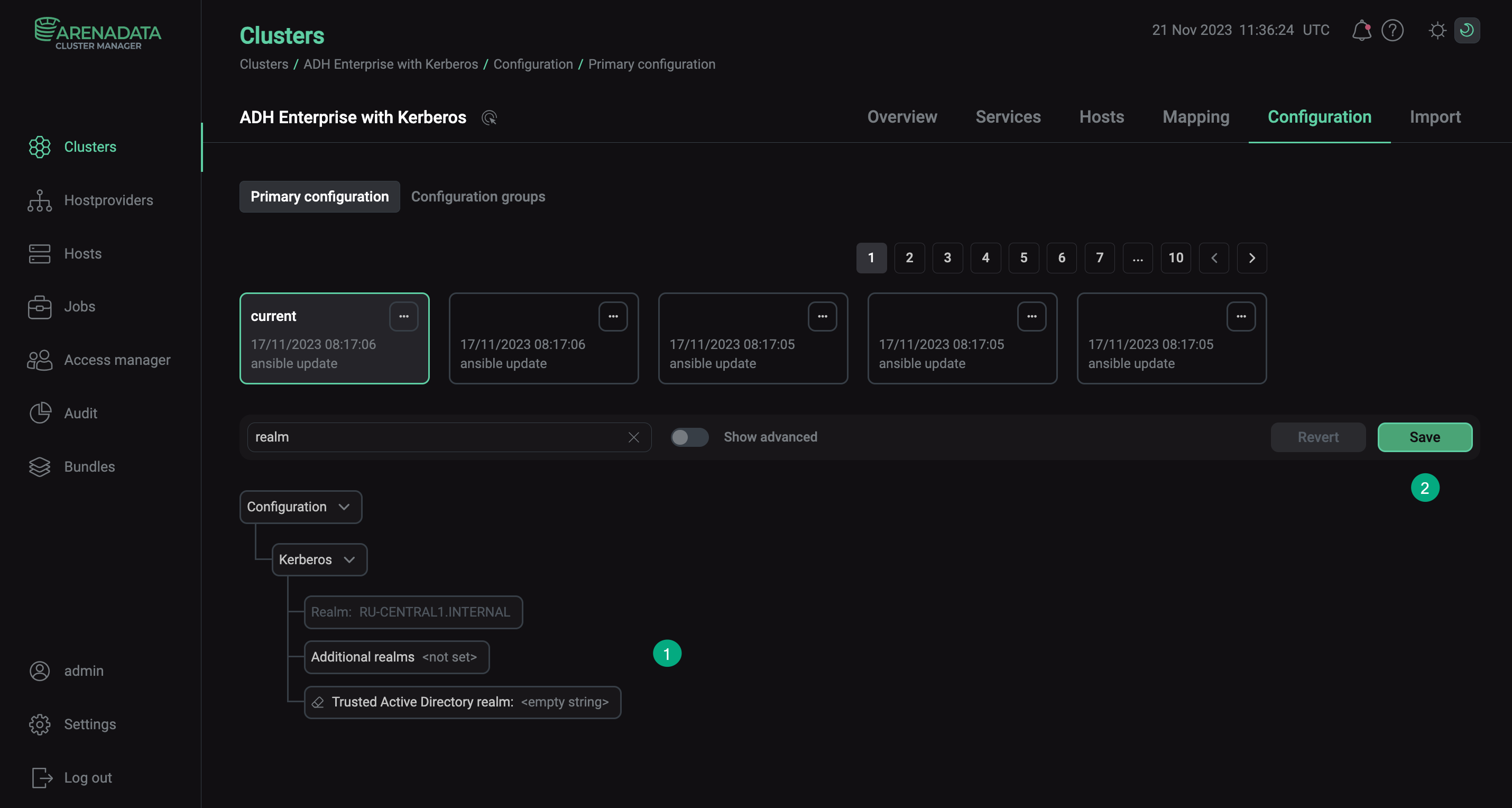 Additional realms parameter in ADCM
Additional realms parameter in ADCM -
Enable Kerberos on both clusters. Check the Advanced flag, then click Existing MIT KDC, and fill in the parameters:
-
KDC hosts;
-
Realm;
-
Kadmin server;
-
Kadmin principal;
-
Kadmin password.
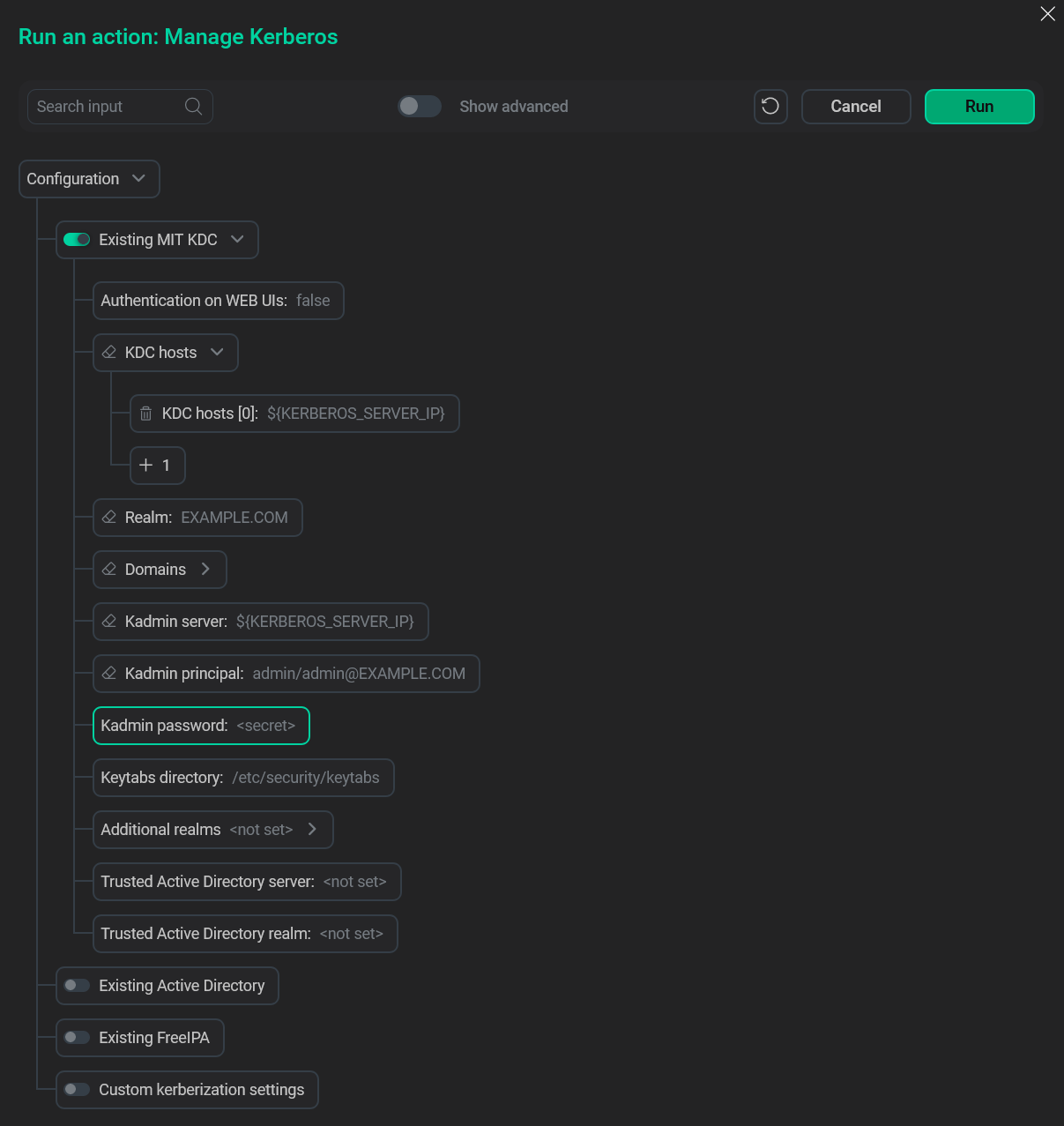 Manage Kerberos action window
Manage Kerberos action window
-
Use distcp
-
Connect to a cluster’s host via SSH and log in as the HDFS principal:
$ kinit hdfs -
Run the
distcpcommand:$ hadoop distcp hdfs://<nameservice1>:8020/<source directory> hdfs://<nameservice2>:8020/<target directory>Where:
-
<nameservice1>— the cluster nameservice from which you want to copy the data; -
<nameservice2>— the cluster nameservice to which the data must be copied; -
<source directory>— the directory of the data you want to copy; -
<target directory>— the directory in which to store the data.
-